在线咨询
专属客服在线解答,提供专业解决方案
声网 AI 助手
您的专属 AI 伙伴,开启全新搜索体验


关键词:对话式 AI | 语音智能体 | Voice Agent | VAD | 轮次检测 | 声网 | TEN
GPT-4o 所展示对话式 AI 的新高度,正一步步把我们在电影《Her》中看到的 AI 语音体验变成现实。AI 的语音交互正在变得更丰富、更流畅、更易用,成为构建多模态智能体的重要组成部分。
但是,“最后一公里”的挑战仍然存在:Voice Agent 依然不像真人一样交谈。
在真实对话里,插话、停顿、甚至讲话重叠都很常见。如果语音 AI 的回应太早、太晚、或者干脆没有回应,整个用户体验就会变得很“出戏”。对话中的“怎么说”往往比“说了什么”更重要。一段停顿可能代表犹豫、礼貌、自信等不同含义。为了让语音 AI 真正像人类一样交谈,它不能只是“听见”并“答复”——它需要真正倾听、理解上下文、并自然地应对。
为了解决以上问题,为大家介绍两款新模型:
- TEN VAD(语音活动检测)
- TEN Turn Detection(轮次检测)
这两个模型是由声网和RTE开发者社区主要支持,基于声网十余年实时语音深度研究成果与超低延迟技术积累所打造的高性能模型,能够让 AI Agent 的交互体验更加自然,任何人都可以自由使用。这两款模型也将作为开源对话式 AI 生态体系 TEN 的核心模块持续迭代优化。
TEN VAD:超低延迟、低功耗、高准确率的语音活动检测模型
TEN VAD 是一个基于深度学习的轻量级流式语音活动检测模型,具备低延迟、低功耗、高准确率等优势。它通常用于语音输入大语言模型(LLM)前的预处理步骤,准确识别是否音频中包含人声并过滤掉无效音频(例如背景噪音或静音段)。
虽然它的功能简单,但作用十分强大:
- 准确识别音频帧中是否有人声;
- 判断一句话的开始和结束位置;
- 过滤掉无关音频(背景噪音、静音等);
这不仅提升了 STT 的准确性,还能显著降低处理成本–避免将无意义的声音送入到 STT 流程中从而产生费用。同时,如果你会用到“轮次检测(Turn Detection)”,那么 VAD 是你的必选项,它是轮次检测准确性的可靠保障。
| 性能对比
与目前常用的 WebRTC Pitch VAD 和 Silero VAD 相比,在公开的 TEN VAD 测试集上(来自多场景、逐帧人工标注),TEN VAD 展示出了更优的效果。
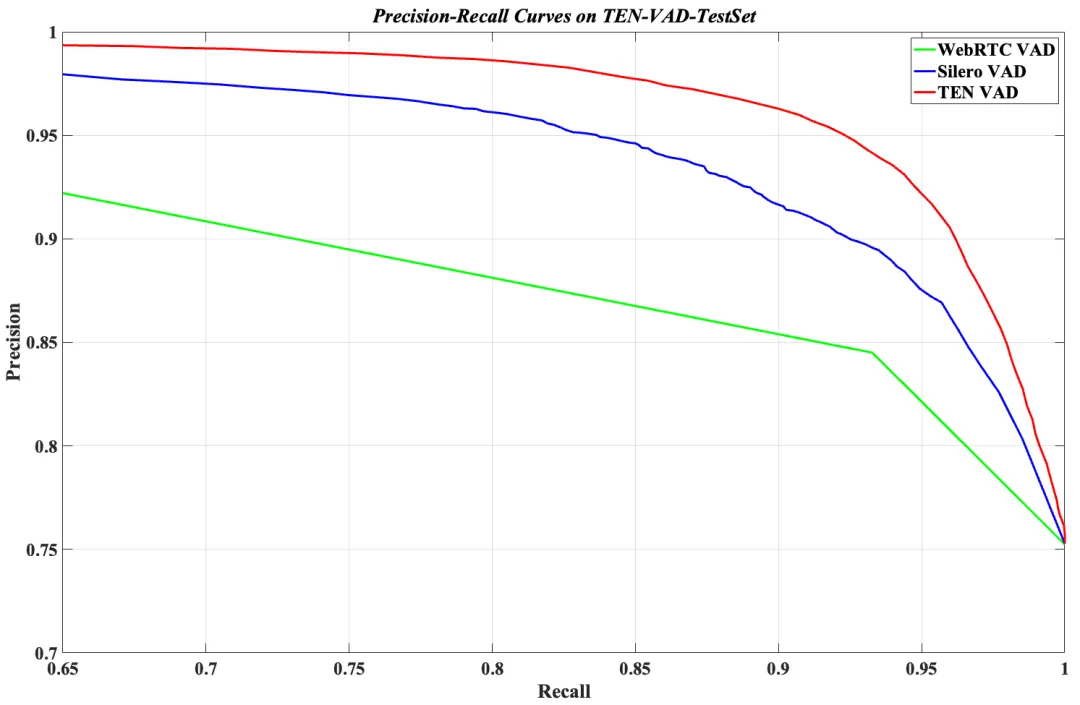
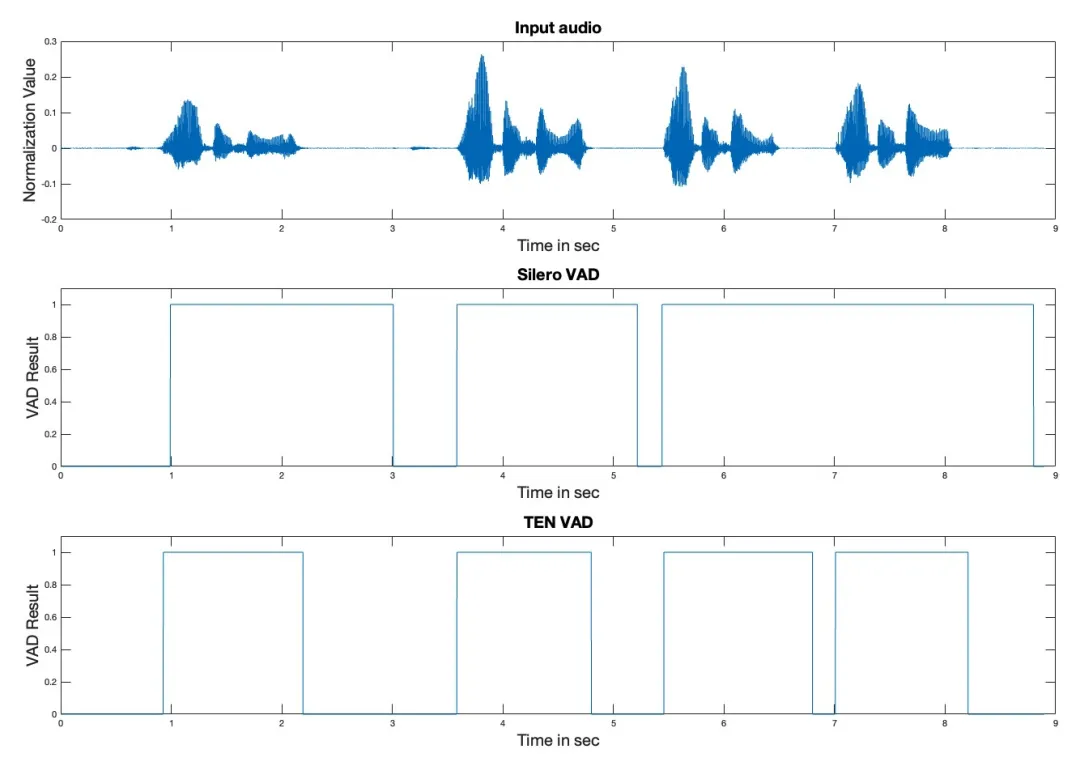
在延迟方面 TEN VAD 同样领先。它能快速检测语音与非语音之间的切换,而 Silero VAD 则存在数百毫秒的延迟,导致人机交互系统的端到端延迟和打断延迟增加。
| 开发者友好
开发者可以在Hugging Face 和 GitHub 上获取和使用TEN VAD,并附带人工精标的数据集(TEN VAD Test Sample),开发者可以一键使用进行模型推理或模型评估。
| 开发者友好
一个真实用户案例显示,使用 TEN VAD 后,音频传输数据量减少了 62%,显著降低了语音服务成本。
在 Hugging Face 和 GitHub 上试用 TEN VAD
- https://huggingface.co/TEN-framework/ten-vad
- https://github.com/TEN-framework/ten-vad
TEN Turn Detection:让 Voice Agent 学会“何时说、何时听”
TEN Turn Detection 重在解决人机对话中最难的部分之一——判断用户何时停止说话。在真实交流中,AI 需要区分出“中途停顿”与“说完了”的差别。插话太早会打断人类思路,太迟回应则会显得迟钝、不自然。
TEN Turn Detection 支持全双工语音交互,即允许用户和 AI 同时说话,就像两个人交流时那样自然。
| 工作原理
它不仅识别语音内容,还通过分析语言模式,判断说话者是在思考、犹豫,还是已经表达完毕;最终让 AI 更智能地决定“该说”还是“该听”,从而让对话更加流畅自然。
该模型支持中英文,可供所有 Voice Agent 开发者自由使用。
| 效果表现
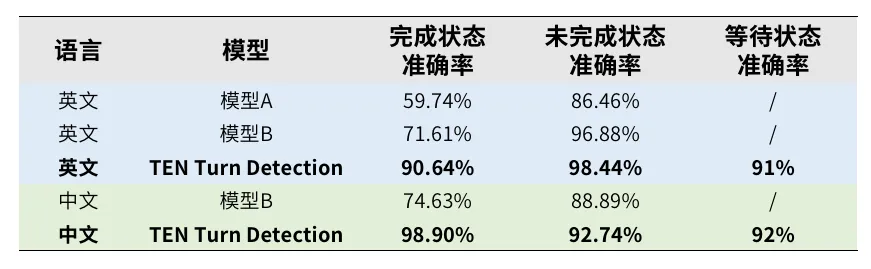
我们在多场景测试数据集上对比了 TEN Turn Detection 和其他同类开源模型,各模型的表现如下:
在 Hugging Face 和 GitHub 上试用 TEN Turn Detection
- https://huggingface.co/TEN-framework/TEN_Turn_Detection
- https://github.com/TEN-framework/ten-turn-detection
为什么选择 TEN VAD 和 TEN Turn Detection?
当结合使用这两个模型时可以打造出更自然、反应更迅速、成本更低的 Voice Agent:
| 高质量
- 基于声网十多年实时语音深度研究经验;
- 超低延迟、低功耗、高准确率;
| 更自然的对话
- 正确处理“打断”、“停顿”、“回应”等人类式交互;
- 极大提升用户体验。
| 成本更低
- VAD 准确识别语音帧,有效减少语音识别调用量;
- 实测结果显示:两者合用能大幅降低总系统成本。
| 即插即用
- 可作为 TEN Framework 的插件模块使用;
- 对于已经使用 TEN Framework 的开发者,支持无缝集成;
- 对于正在选型 AI Agent 框架的团队,TEN 是具备最佳 VAD 和轮次检测能力的选择之一。
使用 TEN VAD 和 TEN Turn Detection 的最佳实践
两款模型都可以搭配 TEN Agent(基于 TEN Framework 的 Voice Agent)使用,视频中展示了TEN Agent中使用TEN Turn Detection前后的差异。
【TEN 加上开源模型 Turn Detection (语轮检测)效果对比 | 打造更智能的对话打断效果】
| Hugging Face 上快速运行(推荐)
1.登录 Hugging Face;
2.打开 TEN Agent Demo;
3.点击右上角设置 > Duplicate this Space;
4.即可用 Hugging Face 提供的 GPU 部署完整体验。
| 本地运行(自带 GPU)
1.登录 Hugging Face;
2.打开 Demo 页右上角设置 > Run Locally;
3.按照本地部署指南操作即可运行完整。(https://github.com/TEN-framework/ten-framework)
| 本地运行(自带 GPU)在对话式 AI 的新时代,打造真正“像人”的 Voice Agent
欢迎关注 TEN 系列产品的更新:
- X / Twitter: @TenFramework
- LinkedIn: Ten Framework
- Medium: ten-framework.medium.com

